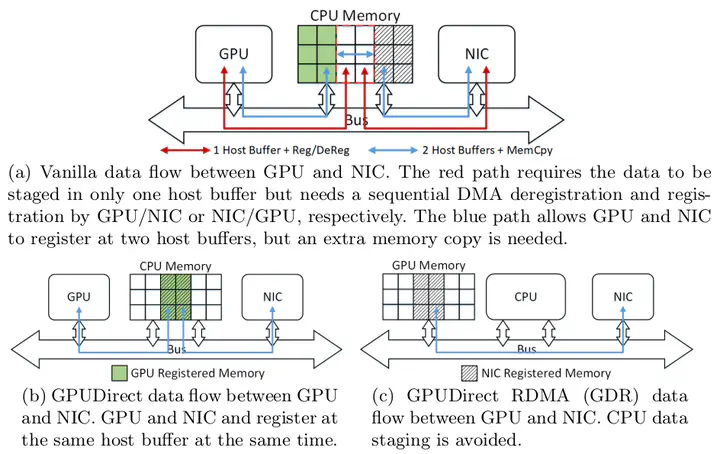
Abstract
The extreme-scale computing landscape is increasingly dominated by GPU-accelerated systems. At the same time, in-situ workflows that employ memory-to-memory inter-application data exchanges have emerged as an effective approach for leveraging these extreme-scale systems. In the case of GPUs, GPUDirect RDMA enables third-party devices, such as network interface cards, to access GPU memory directly and has been adopted for intra-application communications across GPUs. In this paper, we present an interoperable framework for GPU-based in-situ workflows that optimizes data movement using GPUDirect RDMA. Specifically, we analyze the characteristics of the possible data movement pathways between GPUs from an in-situ workflow perspective, and design a strategy that maximizes throughput. Furthermore, we implement this approach as an extension of the DataSpaces data staging service, and experimentally evaluate its performance and scalability on a current leadership GPU cluster. The performance results show that the proposed design reduces data-movement time by up to 53% and 40% for the sender and receiver, respectively, and maintains excellent scalability for up to 256 GPUs.